 Spring数据缓冲区与编解码器详解
Spring数据缓冲区与编解码器详解
# 一、Spring中提供的数据缓冲区和编解码器
Java NIO 提供了 ByteBuffer,但许多库都在其基础上构建了自己的字节缓冲区 API,尤其是在网络操作中,重用缓冲区和/或使用直接缓冲区对性能有益。
例如,Netty 有 ByteBuf 层次结构,Undertow 使用 XNIO,Jetty 使用带有回调的池化字节缓冲区以进行释放,等等。
spring-core 模块提供了一组抽象,用于处理各种字节缓冲区 API,如下所示:
DataBufferFactory抽象了数据缓冲区的创建DataBuffer表示一个字节缓冲区,它可以是池化的DataBufferUtils提供了数据缓冲区的实用方法Codecs将数据缓冲区流解码或编码为更高级别的对象
# 二、DataBufferFactory
DataBufferFactory 用于以两种方式创建数据缓冲区:
- 分配一个新的数据缓冲区,可以选择预先指定容量(如果已知),这更有效,即使
DataBuffer的实现可以根据需要增长和缩小 - 包装现有的
byte[]或java.nio.ByteBuffer,它使用DataBuffer实现来修饰给定的数据,并且不涉及分配
用法示例:
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferFactory;
import org.springframework.core.io.buffer.DefaultDataBufferFactory;
public class DataBufferFactoryExample {
public static void main(String[] args) {
// 创建一个默认的 DataBufferFactory
DataBufferFactory bufferFactory = new DefaultDataBufferFactory();
// 分配一个指定容量的 DataBuffer
DataBuffer buffer1 = bufferFactory.allocateBuffer(1024);
System.out.println("Buffer 1 capacity: " + buffer1.capacity());
// 包装一个 byte 数组
byte[] data = "Hello, DataBuffer!".getBytes();
DataBuffer buffer2 = bufferFactory.wrap(data);
System.out.println("Buffer 2 size: " + buffer2.readableByteCount());
}
}
请注意,WebFlux 应用程序不直接创建 DataBufferFactory,而是通过客户端的 ServerHttpResponse 或 ClientHttpRequest 访问它。工厂的类型取决于底层的客户端或服务器,例如,Reactor Netty 的 NettyDataBufferFactory,其他类型的 DefaultDataBufferFactory。
# 三、DataBuffer
DataBuffer 接口提供与 java.nio.ByteBuffer 类似的操作,但也带来了一些额外的好处,其中一些灵感来自 Netty ByteBuf。以下是部分好处列表:
- 使用独立的读写位置进行读写,即不需要调用
flip()在读写之间切换 - 容量根据需要扩展,如
java.lang.StringBuilder - 池化缓冲区和通过
PooledDataBuffer进行引用计数 - 将缓冲区视为
java.nio.ByteBuffer、InputStream或OutputStream - 确定给定字节的索引或最后一个索引
用法示例:
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferFactory;
import org.springframework.core.io.buffer.DefaultDataBufferFactory;
import java.nio.charset.StandardCharsets;
public class DataBufferExample {
public static void main(String[] args) {
DataBufferFactory bufferFactory = new DefaultDataBufferFactory();
DataBuffer buffer = bufferFactory.allocateBuffer();
// 写入数据
String message = "Hello, DataBuffer!";
byte[] bytes = message.getBytes(StandardCharsets.UTF_8);
buffer.write(bytes);
// 读取数据
byte[] readBytes = new byte[buffer.readableByteCount()];
buffer.read(readBytes);
String readMessage = new String(readBytes, StandardCharsets.UTF_8);
System.out.println("Original message: " + message);
System.out.println("Read message: " + readMessage);
// 释放资源 (如果使用 pooled buffer)
// DataBufferUtils.release(buffer);
}
}
# 四、PooledDataBuffer
正如 ByteBuffer (opens new window) 的 Javadoc 中所解释的,字节缓冲区可以是直接的或非直接的。直接缓冲区可能驻留在 Java 堆之外,这消除了对本机 I/O 操作进行复制的需要。这使得直接缓冲区对于通过套接字接收和发送数据特别有用,但它们的创建和释放成本也更高,这导致了池化缓冲区的想法。
PooledDataBuffer 是 DataBuffer 的扩展,它有助于引用计数,这对于字节缓冲区池化至关重要。它是如何工作的?当分配 PooledDataBuffer 时,引用计数为 1。调用 retain() 会增加计数,而调用 release() 会减少计数。只要计数大于 0,就保证不会释放缓冲区。当计数减少到 0 时,可以释放池化的缓冲区,这在实践中可能意味着为缓冲区保留的内存返回到内存池。
用法示例:
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferFactory;
import org.springframework.core.io.buffer.DefaultDataBufferFactory;
import org.springframework.core.io.buffer.PooledDataBuffer;
import org.springframework.core.io.buffer.DataBufferUtils;
public class PooledDataBufferExample {
public static void main(String[] args) {
DataBufferFactory bufferFactory = new DefaultDataBufferFactory(true); // 创建一个PooledDataBufferFactory
DataBuffer buffer = bufferFactory.allocateBuffer();
// 写入数据
String message = "Hello, PooledDataBuffer!";
byte[] bytes = message.getBytes();
buffer.write(bytes);
// 使用 retain 增加引用计数
DataBufferUtils.retain(buffer);
// 释放资源
DataBufferUtils.release(buffer);
}
}
重要提示: 使用 PooledDataBuffer 时,务必确保正确释放资源,否则会导致内存泄漏。
请注意,与其直接操作 PooledDataBuffer,不如在大多数情况下使用 DataBufferUtils 中的便捷方法,这些方法仅在 DataBuffer 是 PooledDataBuffer 的实例时才将释放或保留应用于 DataBuffer。
# 五、DataBufferUtils
DataBufferUtils 提供了许多用于操作数据缓冲区的实用方法:
- 将数据缓冲区流连接到单个缓冲区中,可能通过零复制,例如,通过复合缓冲区(如果底层字节缓冲区 API 支持)
- 将
InputStream或 NIOChannel转换为Flux<DataBuffer>,反之将Publisher<DataBuffer>转换为OutputStream或 NIOChannel - 如果缓冲区是
PooledDataBuffer的实例,则释放或保留DataBuffer的方法 - 跳过或从字节流中获取直到特定的字节计数
用法示例:
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferFactory;
import org.springframework.core.io.buffer.DefaultDataBufferFactory;
import org.springframework.core.io.buffer.DataBufferUtils;
import reactor.core.publisher.Flux;
import java.nio.charset.StandardCharsets;
public class DataBufferUtilsExample {
public static void main(String[] args) {
DataBufferFactory bufferFactory = new DefaultDataBufferFactory();
// 创建多个 DataBuffer
DataBuffer buffer1 = bufferFactory.wrap("Hello, ".getBytes(StandardCharsets.UTF_8));
DataBuffer buffer2 = bufferFactory.wrap("DataBufferUtils!".getBytes(StandardCharsets.UTF_8));
// 将多个 DataBuffer 合并为一个 Flux
Flux<DataBuffer> flux = Flux.just(buffer1, buffer2);
// 使用 DataBufferUtils.join 合并 DataBuffer
DataBuffer joinedBuffer = DataBufferUtils.join(flux).block();
// 读取合并后的数据
byte[] joinedBytes = new byte[joinedBuffer.readableByteCount()];
joinedBuffer.read(joinedBytes);
String joinedMessage = new String(joinedBytes, StandardCharsets.UTF_8);
System.out.println("Joined message: " + joinedMessage);
// 释放资源
DataBufferUtils.release(joinedBuffer);
}
}
# 六、Codecs
org.springframework.core.codec 包提供了以下策略接口:
Encoder用于将Publisher<T>编码为数据缓冲区流Decoder用于将Publisher<DataBuffer>解码为更高级别的对象流
spring-core 模块提供了 byte[]、ByteBuffer、DataBuffer、Resource 和 String 编码器和解码器的实现。spring-web 模块添加了 Jackson JSON、Jackson Smile、JAXB2、Protocol Buffers 和其他编码器和解码器。
用法示例:
import org.springframework.core.ResolvableType;
import org.springframework.core.codec.StringDecoder;
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferFactory;
import org.springframework.core.io.buffer.DefaultDataBufferFactory;
import reactor.core.publisher.Flux;
import java.nio.charset.StandardCharsets;
import java.util.Map;
public class CodecExample {
public static void main(String[] args) {
DataBufferFactory bufferFactory = new DefaultDataBufferFactory();
StringDecoder stringDecoder = StringDecoder.allMimeTypes();
// 创建一个 DataBuffer
DataBuffer buffer = bufferFactory.wrap("Hello, Codec!".getBytes(StandardCharsets.UTF_8));
// 使用 StringDecoder 解码 DataBuffer
Flux<String> decodedFlux = stringDecoder.decode(Flux.just(buffer), ResolvableType.forInstance(String.class), null);
// 打印解码后的字符串
decodedFlux.subscribe(System.out::println);
}
}
# 七、使用 DataBuffer
在使用数据缓冲区时,必须特别注意确保释放缓冲区,因为它们可能是 池化的。我们将使用编解码器来说明它是如何工作的,但这些概念更普遍适用。让我们看看编解码器必须在内部做些什么来管理数据缓冲区。
Decoder 是在创建更高级别的对象之前读取输入数据缓冲区的最后一个,因此它必须按如下方式释放它们:
- 如果
Decoder只是简单地读取每个输入缓冲区并准备好立即释放它,则可以通过DataBufferUtils.release(dataBuffer)来完成 - 如果
Decoder使用Flux或Mono运算符(例如flatMap、reduce等)来预取和缓存数据项,或者使用诸如filter、skip之类的运算符来忽略数据项,则必须将doOnDiscard(DataBuffer.class, DataBufferUtils::release)添加到组合链中,以确保在丢弃这些缓冲区之前释放它们,这可能是由于错误或取消信号导致的 - 如果
Decoder以任何其他方式持有一个或多个数据缓冲区,则必须确保在完全读取它们时释放它们,或者在缓存的数据缓冲区被读取和释放之前发生的错误或取消信号的情况下释放它们
请注意,DataBufferUtils#join 提供了一种安全有效的方法,可以将数据缓冲区流聚合到单个数据缓冲区中。同样,skipUntilByteCount 和 takeUntilByteCount 是解码器使用的其他安全方法。
Encoder 分配其他人必须读取(和释放)的数据缓冲区。因此,Encoder 没有太多事情要做。但是,如果在使用数据填充缓冲区时发生序列化错误,Encoder 必须注意释放数据缓冲区。例如:
DataBuffer buffer = factory.allocateBuffer();
boolean release = true;
try {
// serialize and populate buffer..
// 序列化并填充缓冲区..
release = false;
}
finally {
if (release) {
DataBufferUtils.release(buffer);
}
}
return buffer;
Encoder 的使用者负责释放它接收到的数据缓冲区。在 WebFlux 应用程序中,Encoder 的输出用于写入 HTTP 服务器响应或客户端 HTTP 请求,在这种情况下,释放数据缓冲区的责任在于写入服务器响应或客户端请求的代码。
好的,我们来深入探讨 DataBuffer API 在 Spring WebFlux 中的实际应用,特别是聚焦于 HttpMessageReader 和 HttpMessageWriter 这两个关键组件。
# 八、WebFlux中对于缓冲区的应用
在 Spring WebFlux 框架中,DataBuffer API 的应用可谓是核心和普遍的。
WebFlux 作为 Spring 家族的响应式 Web 框架,其构建的基石就是非阻塞 I/O 和响应式编程。而 DataBuffer 正是 WebFlux 实现高效、非阻塞数据处理的关键抽象。
# 1、WebFlux 的数据处理管道:DataBuffer 流
WebFlux 框架处理 HTTP 请求和响应时,所有的数据都以 Flux<DataBuffer> 的形式进行流动。这意味着无论是请求体 (Request Body) 还是响应体 (Response Body),在 WebFlux 的内部都被表示为一系列 DataBuffer 组成的流。
- 请求处理:当 WebFlux 接收到一个 HTTP 请求时,请求体的数据不会一次性加载到内存,而是被分块读取并封装成
DataBuffer。这些DataBuffer随后会被发布到一个Flux流中,供后续的请求处理流程使用 - 响应处理:同样,当 WebFlux 需要构建 HTTP 响应时,响应体的数据也需要转换为
DataBuffer流。WebFlux 会将应用程序生成的响应数据 (例如,一个对象、一个字符串、一个文件等) 转换为Flux<DataBuffer>,然后将这个流发送到客户端
# 2、HttpMessageReader 和 HttpMessageWriter:编解码的关键
为了在 Flux<DataBuffer> 流和应用程序更容易处理的数据类型(例如,Java 对象、字符串等)之间进行转换,WebFlux 引入了 HttpMessageReader 和 HttpMessageWriter 接口。它们在 WebFlux 中扮演着 HTTP 消息编解码器 的角色,负责将 DataBuffer 流解码为应用程序对象,以及将应用程序对象编码为 DataBuffer 流。
HttpMessageReader(消息读取器):- 作用:
HttpMessageReader负责读取 HTTP 请求体,并将请求体中的Flux<DataBuffer>流 解码 成应用程序可以理解的对象 - 工作流程:
- WebFlux 接收到请求后,会根据请求的
Content-Type头信息,选择合适的HttpMessageReader来处理请求体 HttpMessageReader从请求中获取Flux<DataBuffer>流HttpMessageReader根据自身的能力(例如,它可能是 JSON 解码器、文本解码器、XML 解码器等),将DataBuffer流中的字节数据解码成目标类型 (例如,一个 Java 对象、一个字符串、一个MultiValueMap等)- 解码后的对象会作为处理方法的参数传递给 Controller 或 Handler Function
- WebFlux 接收到请求后,会根据请求的
- 常见实现:Spring WebFlux 提供了多种内置的
HttpMessageReader实现,例如:Jackson2JsonDecoder:用于解码application/json内容类型的请求体,将其转换为 Java 对象 (通常是使用 Jackson 库进行 JSON 反序列化)StringDecoder:用于解码text/*或application/x-www-form-urlencoded等内容类型的请求体,将其转换为字符串ByteArrayDecoder:用于解码任意二进制数据,将其转换为byte[]数组ByteBufferDecoder:用于解码任意二进制数据,将其转换为ByteBufferResourceHttpMessageReader:用于读取资源文件内容MultipartHttpMessageReader:用于处理multipart/form-data类型的请求体,解析文件上传和表单数据FormHttpMessageReader:用于处理application/x-www-form-urlencoded类型的请求体,解析表单数据- ... 等等,Spring WebFlux 提供了丰富的
HttpMessageReader来支持各种常见的 Content-Type
- 作用:
HttpMessageWriter(消息写入器):- 作用:
HttpMessageWriter负责写入 HTTP 响应体,将应用程序生成的响应对象 编码 成Flux<DataBuffer>流,以便发送给客户端 - 工作流程:
- 当 Controller 或 Handler Function 返回响应对象时,WebFlux 会根据响应对象的类型和请求的
Accept头信息 (或者默认的 Content-Type),选择合适的HttpMessageWriter来处理响应 HttpMessageWriter接收应用程序的响应对象HttpMessageWriter根据自身的能力(例如,JSON 编码器、文本编码器、文件写入器等),将响应对象 编码 成Flux<DataBuffer>流- 编码后的
Flux<DataBuffer>流会作为 HTTP 响应体发送给客户端
- 当 Controller 或 Handler Function 返回响应对象时,WebFlux 会根据响应对象的类型和请求的
- 常见实现:Spring WebFlux 同样提供了多种内置的
HttpMessageWriter实现,与HttpMessageReader类似,例如:Jackson2JsonEncoder:用于编码 Java 对象为application/json格式的响应体 (使用 Jackson 库进行 JSON 序列化)StringEncoder:用于编码字符串为text/*或其他文本类型的响应体ByteArrayEncoder:用于编码byte[]数组为二进制响应体ByteBufferEncoder:用于编码ByteBuffer为二进制响应体ResourceHttpMessageWriter:用于将资源文件作为响应体发送 (例如,静态文件服务)MultipartHttpMessageWriter:用于构建multipart/form-data类型的响应体ServerSentEventHttpMessageWriter:用于处理 Server-Sent Events (SSE) 响应,将事件数据流编码为Flux<DataBuffer>- ... 等等,同样提供了丰富的
HttpMessageWriter支持各种响应类型
- 作用:
# 3、DataBuffer 流在 WebFlux 中的流动示意图
为了更直观地理解 DataBuffer 流在 WebFlux 中的作用,可以简单地用示意图表示:
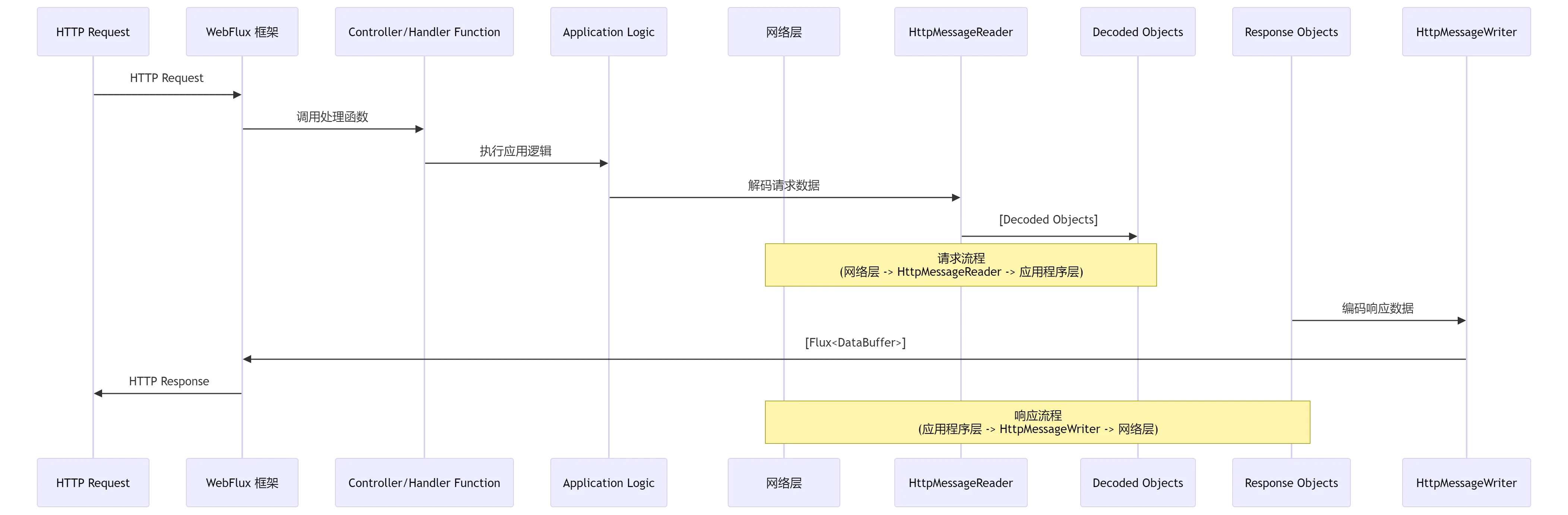
# 4、实际应用场景示例
处理 JSON 请求和响应:
- 当客户端发送
Content-Type: application/json的 POST 请求时,Jackson2JsonDecoder会被用来将请求体的Flux<DataBuffer>解码成 Java 对象 - 当 Controller 方法返回一个 Java 对象并希望以 JSON 格式响应时,
Jackson2JsonEncoder会被用来将该对象编码成Flux<DataBuffer>,并设置响应头Content-Type: application/json
- 当客户端发送
文件上传和下载:
- 文件上传时,
MultipartHttpMessageReader会解析multipart/form-data请求,将文件内容以Flux<DataBuffer>的形式提供给应用程序 - 文件下载时,
ResourceHttpMessageWriter可以将服务器上的文件资源转换为Flux<DataBuffer>,作为响应体流式发送给客户端,实现高效的文件传输
- 文件上传时,
Server-Sent Events (SSE):
- 使用
ServerSentEventHttpMessageWriter可以将服务器端产生的事件数据流编码为Flux<DataBuffer>,并以text/event-stream内容类型发送给客户端,实现服务器推送功能
- 使用
好的,我们来探讨如何使用 DataBuffer 在 Spring WebFlux 中实现高效的文件下载,并创建一个名为 "### 使用DataBuffer进行文件下载" 的章节。
# 九、使用DataBuffer进行文件下载
在传统的 Servlet 容器中,文件下载通常涉及将整个文件加载到内存,然后通过 OutputStream 写入响应。这种方式对于大文件来说效率低下且消耗大量内存。
而在 Spring WebFlux 中,利用 DataBuffer 和响应式流的特性,我们可以实现非阻塞、高效且内存友好的文件下载。
1. DataBuffer 在文件下载中的优势
使用 DataBuffer 进行文件下载的核心优势在于其 非阻塞 I/O 和 流式处理 能力。
- 非阻塞性:
DataBuffer操作是异步和非阻塞的。WebFlux 可以以非阻塞的方式从文件系统中读取数据,并将其写入响应,而不会阻塞服务器线程。这使得服务器能够处理更多的并发请求,提高吞吐量 - 内存效率:文件数据不会一次性加载到内存中。
DataBuffer以小块 (chunk) 的形式读取文件内容,并逐块发送给客户端。这种流式处理方式显著降低了内存占用,特别是在下载大文件时,避免了内存溢出的风险 - 响应式流:
DataBuffer被封装在Flux<DataBuffer>流中,与 WebFlux 的响应式编程模型完美契合。我们可以利用 Reactor 的操作符对DataBuffer流进行各种处理,例如限速、转换等,实现更灵活的文件下载逻辑
2. 关键组件和 API
在 WebFlux 中使用 DataBuffer 进行文件下载,主要涉及以下几个关键组件和 API:
Resource接口:Spring 的Resource抽象用于表示各种资源,包括文件系统中的文件。我们可以使用ClassPathResource、FileSystemResource、UrlResource等实现来获取文件资源DataBufferFactory:用于创建DataBuffer实例。通常 WebFlux 会自动配置合适的DataBufferFactory,例如NettyDataBufferFactory或DefaultDataBufferFactoryDataBufferUtils:提供静态工具方法来操作DataBuffer流,例如将InputStream转换为Flux<DataBuffer>ResourceHttpMessageWriter:(隐式使用) WebFlux 的ResourceHttpMessageWriter能够自动将Resource对象转换为Flux<DataBuffer>并写入 HTTP 响应体ResponseEntity:用于构建 HTTP 响应,可以设置响应头信息,例如Content-Type、Content-Disposition、Content-Length等
3. 实现步骤和代码示例
下面是使用 DataBuffer 在 WebFlux 中实现文件下载的步骤和代码示例:
步骤:
- 获取文件
Resource:通过ResourceLoader或直接创建FileSystemResource等方式获取要下载的文件资源 - 构建
ResponseEntity:- 设置响应头
Content-Type,根据文件类型设置合适的 MIME 类型 - 设置
Content-Disposition头,指定下载文件的名称,让浏览器弹出 "另存为" 对话框 - (可选) 设置
Content-Length头,如果可以预先知道文件大小,可以设置此头,方便浏览器显示下载进度 - 将文件
Resource作为ResponseEntity的 body 返回。WebFlux 会自动使用ResourceHttpMessageWriter将Resource转换为Flux<DataBuffer>并写入响应
- 设置响应头
代码示例 (Controller 方法):
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.io.File;
import java.nio.file.Paths;
@RestController
public class FileDownloadController {
@GetMapping("/download/{filename}")
public ResponseEntity<Resource> downloadFile(@PathVariable String filename) {
// 假设文件存储在服务器的 /files 目录下
String filePath = "/files/" + filename;
File file = Paths.get(filePath).toFile();
if (!file.exists() || !file.isFile()) {
return ResponseEntity.notFound().build(); // 文件不存在
}
Resource resource = new FileSystemResource(file);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_OCTET_STREAM); // 设置通用二进制流类型
headers.setContentDispositionFormData("attachment", filename); // 设置下载文件名
headers.setContentLength(file.length()); // (可选) 设置文件大小
return ResponseEntity.ok()
.headers(headers)
.body(resource); // 返回 Resource 对象作为响应体
}
}
代码解释:
@GetMapping("/download/{filename}"):定义文件下载的 API 接口,通过路径参数filename接收文件名FileSystemResource(file):创建FileSystemResource对象,指向要下载的文件HttpHeaders:创建 HTTP 响应头MediaType.APPLICATION_OCTET_STREAM:设置Content-Type为通用二进制流类型,适用于下载任意文件。你可以根据文件类型设置更具体的 MIME 类型,例如MediaType.IMAGE_JPEGfor JPEG 图片setContentDispositionFormData("attachment", filename):设置Content-Disposition头为attachment,并指定下载的文件名,这将告诉浏览器以附件形式下载文件,并弹出 "另存为" 对话框setContentLength(file.length()):(可选) 设置Content-Length头,告知浏览器文件大小,方便显示下载进度
ResponseEntity.ok().headers(headers).body(resource):构建ResponseEntity,状态码为 200 OK,包含设置好的响应头,并将resource对象设置为响应体
4. WebFlux 自动处理 Resource 到 DataBuffer 的转换
关键在于我们直接将 Resource 对象作为 ResponseEntity 的 body 返回。WebFlux 的 ResourceHttpMessageWriter 会自动检测到响应体类型为 Resource,并负责完成以下工作:
- 读取
Resource指向的文件内容 - 使用配置的
DataBufferFactory创建DataBuffer实例 - 将文件内容分块读取到
DataBuffer中 - 将
DataBuffer转换为Flux<DataBuffer>流 - 将
Flux<DataBuffer>流写入 HTTP 响应体,实现流式下载
5. 无法使用Resource的情况
在某些情况下,你可能需要手动处理 InputStream 到 DataBuffer 的转换。
以下是一个示例:
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferUtils;
import org.springframework.core.io.buffer.DataBufferFactory;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Paths;
@RestController
public class InputStreamDownloadController {
private final DataBufferFactory dataBufferFactory; // 注入 DataBufferFactory
public InputStreamDownloadController(DataBufferFactory dataBufferFactory) {
this.dataBufferFactory = dataBufferFactory;
}
@GetMapping("/download/stream/{filename}")
public ResponseEntity<Flux<DataBuffer>> downloadFileAsStream(@PathVariable String filename) {
String filePath = "/files/" + filename; // 文件路径
java.io.File file = Paths.get(filePath).toFile();
if (!file.exists() || !file.isFile()) {
return ResponseEntity.notFound().build();
}
Flux<DataBuffer> dataBufferFlux = DataBufferUtils.readInputStream(
() -> { // InputStream Supplier
try {
InputStream is = ...
return is;
} catch (IOException e) {
throw new RuntimeException("Failed to get InputStream", e); // 异常处理
}
},
dataBufferFactory,
4096 // 缓冲区大小,例如 4KB
).doFinally(signalType -> { // 确保在完成或出错时关闭 InputStream
if (signalType == reactor.core.publisher.SignalType.CANCEL || signalType == reactor.core.publisher.SignalType.ON_ERROR || signalType == reactor.core.publisher.SignalType.ON_COMPLETE) {
// 在这里关闭 InputStream,但 DataBufferUtils.readInputStream 会自动处理关闭,此处通常不需要显式关闭,除非你有更复杂的资源管理需求。
// 注意:DataBufferUtils.readInputStream 在内部已经处理了 InputStream 的关闭,通常不需要在这里再次显式关闭。
}
});
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_OCTET_STREAM);
headers.setContentDispositionFormData("attachment", filename);
headers.setContentLength(file.length()); // (可选) 设置 Content-Length
return ResponseEntity.ok()
.headers(headers)
.body(dataBufferFlux); // 返回 Flux<DataBuffer> 作为响应体
}
}
# 十、最佳实践
- 始终释放 PooledDataBuffer:使用
PooledDataBuffer时,确保在不再需要时立即释放,避免内存泄漏 - 使用 DataBufferUtils 简化操作:
DataBufferUtils提供了许多便捷方法,可以简化数据缓冲区的操作,例如合并、分割、释放等 - 在 WebFlux 中,注意编解码器的使用:在 WebFlux 应用程序中,编解码器负责数据的编码和解码,需要特别注意数据缓冲区的释放,避免资源泄漏
- 选择合适的 DataBufferFactory:根据应用场景选择合适的
DataBufferFactory,例如,对于需要高性能的场景,可以使用NettyDataBufferFactory - 使用 try-finally 确保释放:在编码器中,使用
try-finally块来确保在发生异常时也能释放数据缓冲区
请注意,在 Netty 上运行时,有一些调试选项可用于 排查缓冲区泄漏问题 (opens new window)。
# 十一、总结
本文详细介绍了 Spring Framework 中 DataBufferFactory、DataBuffer、DataBufferUtils 和 Codec 的概念、用法和最佳实践。
通过合理使用这些工具,可以更高效地处理数据流,并避免内存泄漏等问题,提升应用程序的性能和稳定性。
祝你变得更强!