 ELK实践之采集并分析Nginx与应用程序日志
ELK实践之采集并分析Nginx与应用程序日志
# 一、前言
ELK 是由 Elasticsearch、Logstash 和 Kibana 三个组件构成的开源日志分析栈,在企业级日志管理中应用广泛。简单来说:
- Elasticsearch:分布式搜索引擎,负责存储和索引日志数据
- Logstash:数据处理管道,负责收集、解析和转换日志
- Kibana:可视化界面,提供数据查询和图表展示
现在很多公司的运维体系都离不开ELK,特别是微服务架构下,日志分散在各个服务中,通过ELK可以统一收集和分析,大大提升了问题排查效率。
关于 Elasticsearch 的详细介绍,可以参考我之前写的文章:Elasticsearch实战。
本文主要从实践角度出发,手把手教你如何用 ELK 收集 Nginx 访问日志和 Java 应用日志,并进行有效的分析和监控。
# 二、环境准备
在开始之前,我们需要先部署好 ELK 的基础环境。这里推荐使用 Docker 方式,简单快捷:
# 拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.3.1
docker pull docker.elastic.co/kibana/kibana:7.3.1
docker pull docker.elastic.co/logstash/logstash:7.3.1
具体的安装和配置步骤可以参考官方文档:
安装好基础环境后,我们就可以开始日志收集的实战了。
# 三、采集 Nginx 日志
要收集 Nginx 日志,我们会用到 Filebeat 这个轻量级的日志收集器。可能有人会问,为什么不直接用 Logstash 呢?
简单来说,两者分工不同:
- Filebeat:专门负责日志文件的采集和传输,资源占用小,部署简单
- Logstash:主要负责数据的解析、过滤和转换,功能强大但相对重一些
这样的架构设计让整个系统更加灵活和高效,Filebeat 在各个服务器上收集日志,然后统一发送给 Logstash 进行处理。
# 1、配置 Filebeat 采集 Nginx 日志
首先创建 Filebeat 的配置文件 /etc/filebeat/filebeat.yml:
filebeat.inputs:
- type: log
paths:
- /usr/local/nginx/logs/access.log
fields:
input_type_source: nginx
output.logstash:
hosts: ["172.28.0.1:5044"]
这个配置很简单:
paths指定要监控的日志文件路径fields添加自定义字段,用于后续的分类处理output.logstash指定 Logstash 的地址
接下来启动 Filebeat 容器:
docker run -d --name filebeat-nginx \
-v /usr/local/nginx/:/usr/local/nginx/ \
-v /etc/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml \
docker.elastic.co/beats/filebeat:7.3.1 filebeat -e -d "publish"
注意:这里假设你的 Nginx 安装在
/usr/local/nginx/目录,需要将整个目录挂载到容器中,让 Filebeat 能访问到日志文件。
现在 Nginx 的日志就会被 Filebeat 收集并发送到 Logstash 了,下一步我们需要配置 Logstash 来处理这些日志。
# 2、配置 Logstash 处理日志
Logstash 的核心是数据处理管道(Pipeline),它包含三个阶段:输入、过滤、输出。我们来创建一个处理 Nginx 日志的配置文件 /etc/logstash/pipeline/nginx.conf:
input {
beats {
port => "5044"
}
}
filter {
# 使用 grok 插件解析 Nginx 日志格式
grok {
match => {
"message" => "%{IPORHOST:remote_addr} - %{DATA:remote_user} \[%{HTTPDATE:time_local}\] \"%{NUMBER:request_time}\" \"%{NUMBER:upstream_response_time}?\" \"%{DATA:http_host}\" \"%{DATA:request_uri}\" %{NUMBER:status} %{NUMBER:body_bytes_sent} \"%{DATA:http_referer}\" \"%{DATA:http_user_agent}\" \"%{WORD:request_method}\" \"%{GREEDYDATA:request_body}\""
}
remove_field => "message"
}
# 字段类型转换和添加
mutate {
add_field => { "read_timestamp" => "%{@timestamp}" }
convert => {
"request_time" => "float"
"upstream_response_time" => "float"
"status" => "integer"
"body_bytes_sent" => "integer"
}
}
# 解析 User-Agent 信息
useragent {
source => "http_user_agent"
target => "nginx_http_user_agent"
}
# 时间字段处理
date {
match => [ "time_local", "dd/MMM/YYYY:H:m:s Z" ]
remove_field => "time_local"
}
# IP 地理位置解析
geoip {
source => "remote_addr"
}
}
output {
elasticsearch {
hosts => [ "elasticsearch:9200" ]
user => "elastic"
password => "elastic"
index => "logstash-%{[input][type]}-%{[fields][input_type_source]}-%{+YYYY.MM.dd}"
}
}
接下来创建 Logstash 的主配置文件 /etc/logstash/logstash.yml:
http.host: "0.0.0.0"
# 禁用监控功能(可选)
xpack.monitoring.enabled: false
# 批处理配置
pipeline.batch.size: 1000
pipeline.batch.delay: 500
最后启动 Logstash 容器:
docker run --name logstash --restart=on-failure:3 --net=host -d \
-v /etc/logstash/pipeline/:/usr/share/logstash/pipeline/ \
-v /etc/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml \
docker.elastic.co/logstash/logstash:7.3.1
重要提醒:确保 Elasticsearch 开启了自动创建索引功能,否则 Logstash 会报错无法写入数据。
# 3、理解 Logstash Pipeline
上面的配置体现了 Logstash Pipeline 的三个核心阶段:
- Input(输入):接收来自 Filebeat 的数据
- Filter(过滤):解析和处理日志数据
grok:解析 Nginx 日志格式,提取各个字段mutate:字段类型转换和添加自定义字段useragent:解析浏览器信息date:时间格式处理geoip:根据 IP 获取地理位置
- Output(输出):将处理后的数据发送到 Elasticsearch
这样一个完整的数据处理流程就建立起来了,原本无结构的日志文本被解析成了结构化的数据,方便后续的搜索和分析。
性能调优:如果需要调整 JVM 内存等参数,可以通过挂载
jvm.options文件来实现:-v /etc/logstash/jvm.options:/usr/share/logstash/config/jvm.options
# 4、深入理解 Grok 模式
Grok 是 Logstash 中最重要的插件之一,它能把无结构的日志文本解析成结构化的字段。说白了,就是用正则表达式的升级版来提取你想要的信息。
Grok 的语法很简单:%{PATTERN:field_name},其中:
PATTERN是预定义的匹配模式field_name是提取后的字段名
示例中用到的 Grok 模式:
%{IPORHOST:remote_addr}:提取客户端 IP 地址%{HTTPDATE:time_local}:提取访问时间,格式如29/May/2023:17:30:35 +0800%{NUMBER:request_time}:提取请求处理时间(秒)%{NUMBER:upstream_response_time}?:提取后端响应时间,?表示可选%{DATA:http_host}:提取访问的域名(注意不能用host,会被系统字段覆盖)%{DATA:request_uri}:提取请求的 URI 路径%{NUMBER:status}:提取 HTTP 状态码%{WORD:request_method}:提取请求方法(GET、POST 等)%{GREEDYDATA:request_body}:提取请求体内容
常用的 Grok 模式还有:
%{TIMESTAMP_ISO8601:timestamp}:ISO 8601 时间格式%{USERNAME:username}:用户名格式%{EMAILADDRESS:email}:邮箱地址格式%{URI:uri}:URI 格式
对应的 Nginx 日志格式配置:
log_format main escape=json '$remote_addr - $remote_user [$time_local] "$request_time" "$upstream_response_time" "$host" "$request_uri" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$request_method" "$request_body" ';
实际的日志输出示例:
59.11.219.0 - [29/May/2023:17:30:35 +0800] "0.002" "0.002" "m.x.cn" "/apis/test?Id=29493" 200 8 "https://m.x.cn/auction/live/29493?s=11f231ff" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/99.0.4844.51 Safari/537.36" "GET" ""
调试工具:可以使用 Grok Constructor (opens new window) 在线验证你的 Grok 模式是否正确。
官方文档:更多信息请参考 Grok filter plugin (opens new window)
# 5、避免重复数据
在实际使用中,可能会遇到日志重复采集的问题,比如 Filebeat 重启后重新读取日志文件。这时可以用 fingerprint 插件来去重:
filter {
# ... 其他配置
# 生成日志指纹,用于去重
fingerprint {
source => "message"
target => "[@metadata][fingerprint]"
method => "MD5"
}
}
然后在 output 中使用指纹作为文档 ID:
output {
elasticsearch {
hosts => [ "elasticsearch:9200" ]
user => "elastic"
password => "elastic"
document_id => "%{[@metadata][fingerprint]}"
index => "logstash-%{[input][type]}-%{[fields][input_type_source]}-%{+YYYY.MM.dd}"
}
}
这样相同内容的日志会有相同的文档 ID,Elasticsearch 会自动覆盖重复的文档,实现去重效果。
# 四、采集应用日志
相比 Nginx 访问日志,应用程序日志的采集更加直接。我们可以让应用直接通过网络将日志发送给 Logstash,省去了文件读取的步骤。
# 1、配置应用日志 Pipeline
创建应用日志的配置文件 /etc/logstash/pipeline/app.conf:
input {
tcp {
port => 5045
codec => json_lines
}
}
output {
elasticsearch {
hosts => [ "elasticsearch:9200" ]
user => "elastic"
password => "elastic"
index => "logstash-%{[input][type]}-%{[fields][input_type_source]}-%{+YYYY.MM.dd}"
}
}
这个配置很简洁:
- Input:监听 5045 端口,接收 JSON 格式的日志
- Output:直接发送到 Elasticsearch
由于应用日志通常已经是结构化的 JSON 格式,所以不需要复杂的 Filter 处理。
# 2、Java 应用日志配置
对于 Java 应用,我们可以使用 Logback 的 Logstash 插件,直接将日志通过网络发送到 Logstash。
# 2.1、添加依赖
在 pom.xml 中添加 Logstash Logback 插件:
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.3</version>
</dependency>
# 2.2、配置 Logback
在 logback-spring.xml 中配置:
<configuration>
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>172.28.0.1:5045</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
<root level="INFO">
<appender-ref ref="LOGSTASH" />
</root>
</configuration>
这样配置后,应用的所有日志就会自动发送到 Logstash 了。
简化配置:如果觉得手动配置麻烦,可以使用 logstash-logging-spring-boot-starter (opens new window) 来简化整个过程。
# 五、使用 Kibana 分析日志
数据收集完成后,就可以在 Kibana 中进行查看和分析了。
# 1、创建索引模式
首先进入 Kibana 管理页面,创建索引模式(Index Pattern)。这里以 Nginx 日志为例:
- 进入
Management→Index Patterns - 点击
Create index pattern - 输入索引模式,比如
logstash-log-nginx-* - 选择时间字段
@timestamp
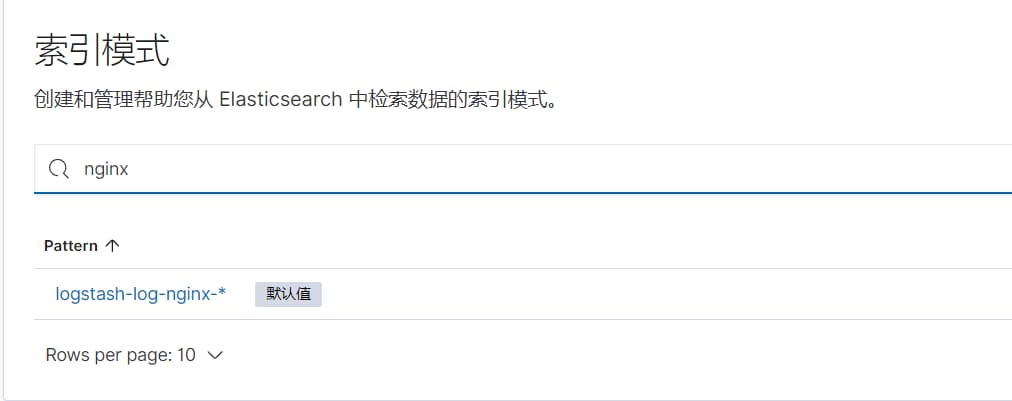
# 2、查看日志数据
创建好索引模式后,点击左侧的 Discover,就能看到实时的日志数据了:
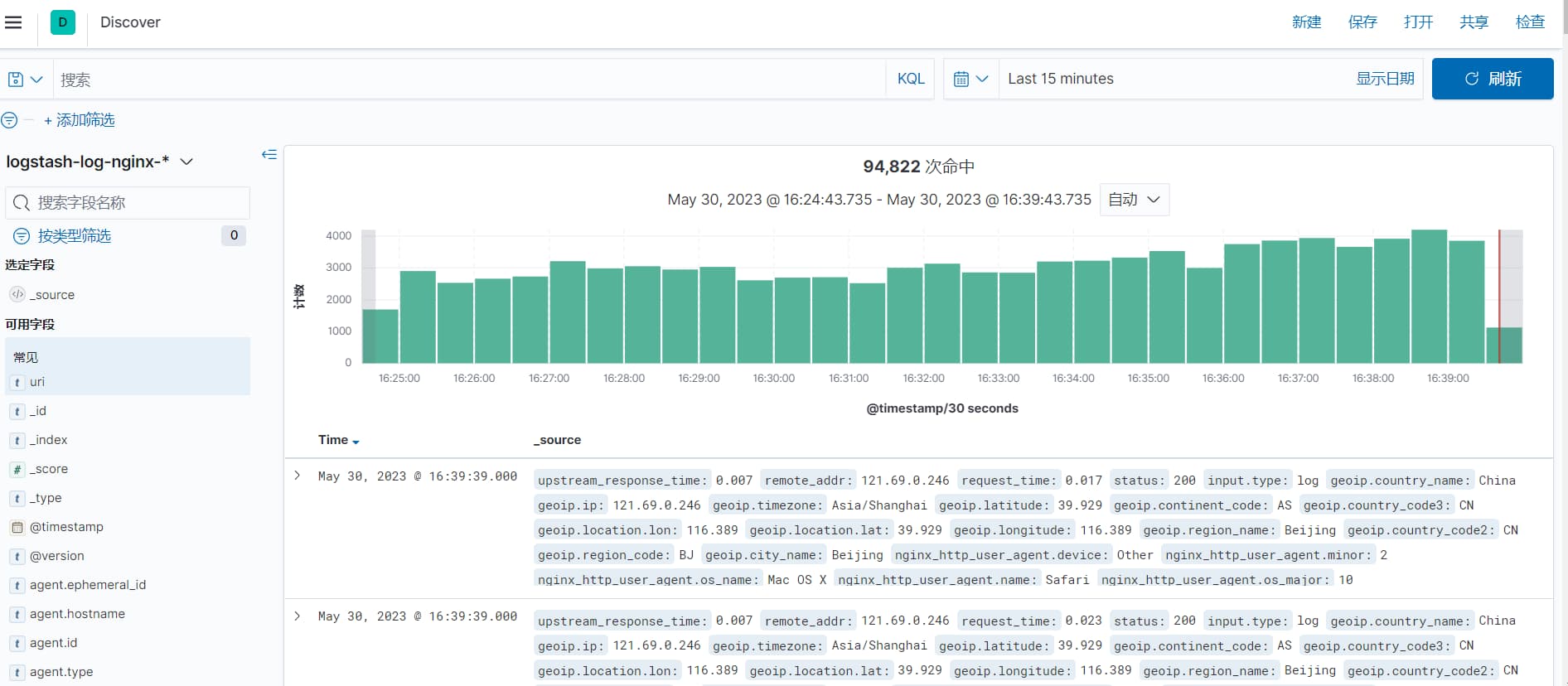
在这里你可以:
- 搜索特定的日志内容
- 按时间范围筛选
- 查看各个字段的统计信息
- 添加或移除显示的字段
# 3、设置数据生命周期
为了避免磁盘空间被大量日志占满,建议设置索引生命周期策略:
- 进入
Management→Index Lifecycle Policies - 创建新的策略,比如设置 30 天后自动删除
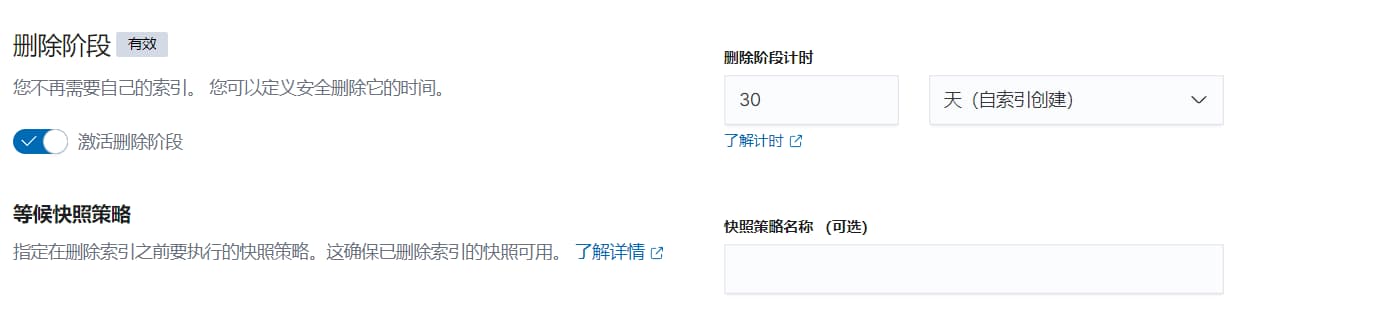
然后将这个策略关联到对应的索引模板上。
# 4、创建可视化图表
你还可以创建各种图表来分析访问趋势、状态码分布、热门页面等。推荐参考:在 Kibana 中可视化 NGINX 访问日志 (opens new window)
# 5、常见问题及解决方案
# 5.1、生命周期策略不生效
有时候会发现设置的生命周期策略不生效,索引到期后没有被删除。这通常是 Kibana 的一个已知问题。
解决方案:可以参考 Elastic 生命周期策略索引不删除的问题 (opens new window) 的解决方法。
# 5.2、搜索结果不符合预期
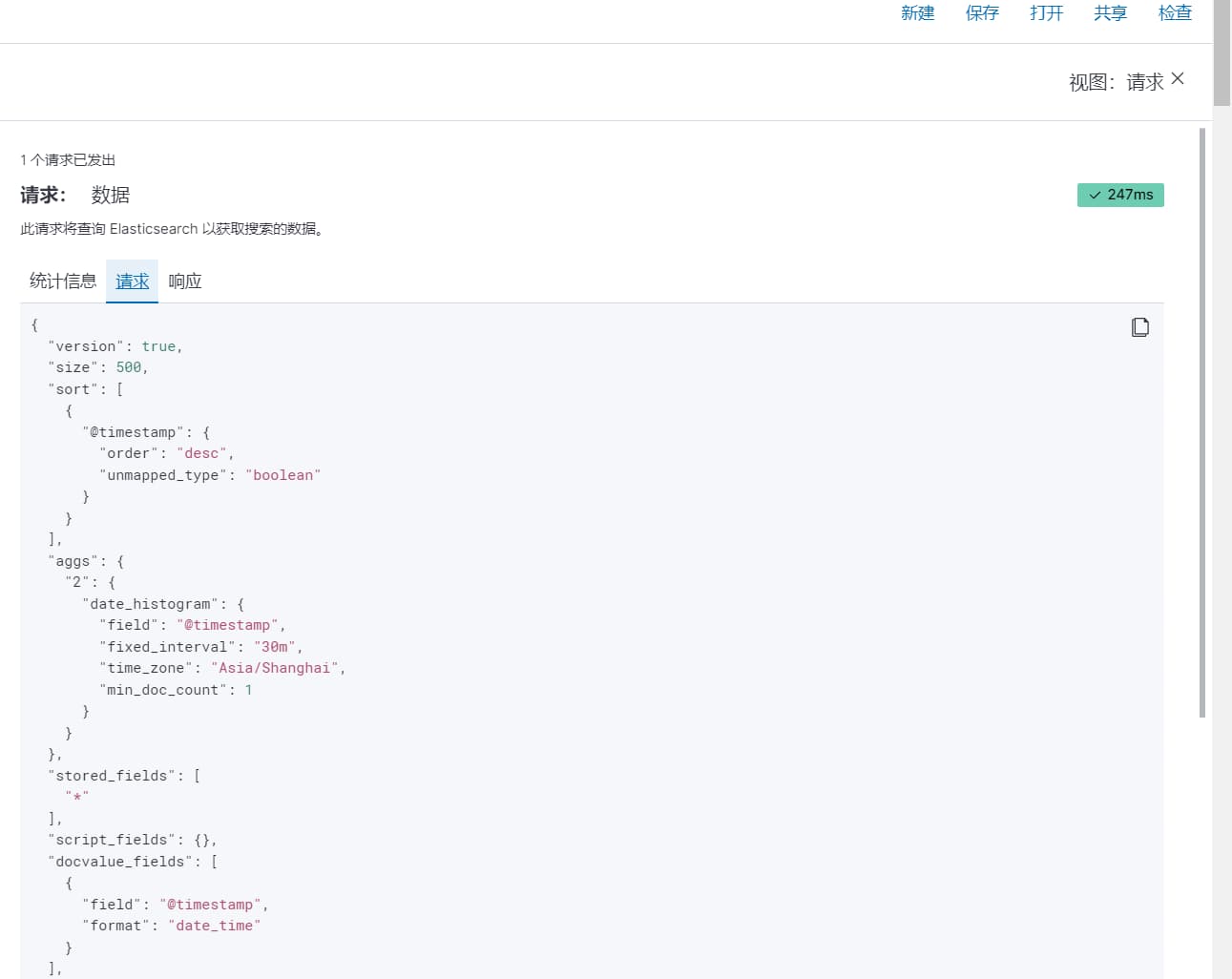
在 Discover 中搜索时,如果结果不符合预期,可以:
- 点击右上角的"检查"查看完整的 ES 查询
- 注意默认是按时间倒序排列的
- 可以点击 "Time" 字段切换排序方式
# 5.3、中文搜索优化
对于中文日志,如果需要更好的搜索体验,可以:
- 为
message字段配置 IK 分词器 - 或者使用
wildcard类型,支持通配符搜索:message : *关键词*
这样可以实现更精确的中文搜索匹配。
# 六、高并发场景优化
当日志量比较大的时候,直接让 Filebeat 发送到 Logstash 可能会造成压力。这时可以引入 Kafka 作为消息中间件,实现削峰填谷。
# 1、架构调整
原本的架构:Filebeat → Logstash → Elasticsearch
优化后的架构:Filebeat → Kafka → Logstash → Elasticsearch
# 2、配置 Kafka 中间件
# 2.1、修改 Filebeat 配置
output.kafka:
hosts: ["192.168.0.1:9092"]
topic: 'nginx'
# 2.2、修改 Logstash 配置
input {
kafka {
type => "kafka"
bootstrap_servers => "192.168.0.1:9092"
topics => "nginx"
group_id => "logstash"
consumer_threads => 2
}
}
这样的好处是:
- 缓冲机制:Kafka 可以暂存大量日志,避免 Logstash 处理不过来
- 水平扩展:可以启动多个 Logstash 实例并行处理
- 数据可靠性:即使 Logstash 宕机,日志也不会丢失
扩展阅读:
# 七、延伸阅读
如果你对日志系统设计感兴趣,推荐阅读 日志的艺术 (opens new window)。
对于超大规模的日志分析场景,除了 ELK,也可以考虑使用 Apache Doris,它从 2.0 版本开始支持倒排索引 (opens new window),在某些场景下可能比传统的 ClickHouse 方案更合适。
# 八、总结
通过本文的实践,我们完整地搭建了一个 ELK 日志分析系统,涵盖了:
- Nginx 访问日志的采集和解析
- Java 应用日志的收集配置
- Kibana 中的数据查看和分析
- 高并发场景下的架构优化
ELK 栈确实是目前最主流的日志分析解决方案,掌握了这套技能,无论是日常运维还是故障排查,都会轻松很多。
祝你变得更强!